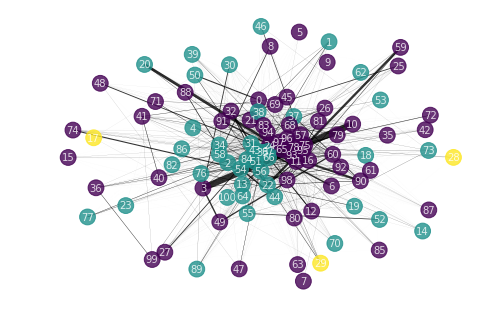
Keyword and Sentence Extraction with TextRank (pytextrank)
Introduction
TextRank is a graph based algorithm for Natural Language Processing that can be used for keyword and sentence extraction. The algorithm is inspired by PageRank which was used by Google to rank websites. For a web page , is the set of webpages pointing to it while is the set of vertices points to. The rank of is defined as:
where d is a damping factor between 0 and 1.
In the case of text, the connections can be weighted so we introduce which is the weight of the edge between entity and . The weighed rank of now becomes:
We have the choice of using words, collocations, or even sentences as vertices of our graph. The same goes for the connection between the vertices.
Keyword extraction
For keyword extraction we want to identify a subset of terms that best describe the text. We follow these steps:
- Tokenize and annotate with Part of Speech (PoS). Only consider single words. No n-grams used, multi-words are reconstructed later.
- Use syntactic filter on all the lexical units (e.g. all words, nouns and verbs only).
- Create and edge if lexical units co-occur within a window of N words to obtain an unweighted undirected graph.
- Run the text rank algorithm to rank the words.
- We take the top lexical words.
- Adjacent keywords are collapsed into a multi-word keyword.
Sentence extraction
Instead of extracting words, we extract sentences that are the most representative of the body of text using these steps:
- Build a graph with a sentence as each node.
- There is a connection between sentence if they are similar - this is measure by common words (after going through a syntactic filter). Similarity between sentences and is given by:
- We get a weighted graph and apply the PageRank algorithm and take the top sentences.
pytextrank
pytextrank is a python implementation of TextRank, with some modifications as described on GitHub, notably verbs are included in the graph but not in the final keywords and lemmatization is used instead of stemming. Note that version 1.1.0 of pytextrank has errors as described in this GitHub issue due to an unused argument Parse=True when calling spacy_nlp. To correct for this modify the source code or use laxatives’ Pull Request. pytextrank is built on spaCy.
This Jupyter notebook shows us how to use pytextrank. In his implementation the author choses to use iterators and write the intermediate results to json files, which can slow things down due to the IO overhead. I have forked the pytextrank repository and modified the functions in order to avoid writing intermediate results to json files. The functions top_keywords_sentences allows the user to get the top keywords and sentences with ease.
def top_keywords_sentences(text,stopwords=None, spacy_nlp=None, skip_ner=True, phrase_limit=15, sent_word_limit=150):
#Parse incoming text
parse=parse_doc(text2json(text))
parse_list=[json.loads(pretty_print(i._asdict())) for i in parse]
#Create and rank graph for keywords
graph, ranks = text_rank(parse_list)
norm_rank=normalize_key_phrases(parse_list, ranks, stopwords=stopwords, spacy_nlp=spacy_nlp, skip_ner=skip_ner)
norm_rank_list=[json.loads(pretty_print(rl._asdict())) for rl in norm_rank ]
phrases = ", ".join(set([p for p in limit_keyphrases(norm_rank_list, phrase_limit=phrase_limit)]))
# return a matrix like result for the top keywords
kernel = rank_kernel(norm_rank_list)
# Rank the sentences
top_sent=top_sentences(kernel, parse_list)
top_sent_list=[json.loads(pretty_print(s._asdict())) for s in top_sent ]
sent_iter = sorted(limit_sentences(top_sent_list, word_limit=sent_word_limit), key=lambda x: x[1])
# Return ranked sentences
s=[]
for sent_text, idx in sent_iter:
s.append(make_sentence(sent_text))
graf_text = " ".join(s)
return(graf_text,phrases)
Written this way, we get the TextRank results faster as intermediary results do not have to be written into json files.
import xang_pytextrank as pyt
import time
text="Compatibility of systems of linear constraints \
over the set of natural numbers.\
Criteria of compatibility of a system of linear\
Diophantine equations,\
strict inequations, and nonstrict inequations are considered.\
Upper bounds for components of a minimal set of solutions and \
algorithms of construction of minimal generating sets of solutions\
for all types of systems are given. These criteria and the \
corresponding algorithms for constructing a minimal\
supporting set of solutions can be used in solving all \
the considered types systems and systems of mixed types."
start=time.time()
phrase,word=pyt.top_keywords_sentences(text,phrase_limit=15)
print('Keywords:',word)
print('Time Taken: ',time.time()-start)
Keywords: mixed types, solutions, natural numbers, constraints, minimal generating sets, minimal set, systems, types, nonstrict inequations
Time Taken: 0.3171839714050293
Using the original implementation with intermediary files:
import pytextrank
path_stage0 = "in.json"
path_stage1 = "o1.json"
path_stage2 = "o2.json"
path_stage3 = "o3.json"
start=time.time()
with open(path_stage1, 'w') as f:
for graf in pytextrank.parse_doc(pytextrank.json_iter(path_stage0)):
f.write("%s\n" % pytextrank.pretty_print(graf._asdict()))
graph, ranks = pytextrank.text_rank(path_stage1)
pytextrank.render_ranks(graph, ranks)
with open(path_stage2, 'w') as f:
for rl in pytextrank.normalize_key_phrases(path_stage1, ranks):
f.write("%s\n" % pytextrank.pretty_print(rl._asdict()))
kernel = pytextrank.rank_kernel(path_stage2)
with open(path_stage3, 'w') as f:
for s in pytextrank.top_sentences(kernel, path_stage1):
f.write(pytextrank.pretty_print(s._asdict()))
f.write("\n")
phrases = ", ".join(set([p for p in pytextrank.limit_keyphrases(path_stage2, phrase_limit=3)]))
sent_iter = sorted(pytextrank.limit_sentences(path_stage3, word_limit=250), key=lambda x: x[1])
s = []
for sent_text, idx in sent_iter:
s.append(pytextrank.make_sentence(sent_text))
graf_text = " ".join(s)
#print("**excerpts:** %s\n\n**keywords:** %s" % (graf_text, phrases,))
print('Time Taken: ',time.time()-start)
Time Taken: 1.5418004989624023
Using TextRank
TextRank is unsupervised and does not depend on language. As such the algorithm can be used for other languages. We would need a syntactic filter in our language of choice if we choose to filter out verbs. The output from TextRank can be used to summarize the text or as machine learning features.
We take a look at sample paper abstracts from Semantic Scholar. Data is also available in this folder with the file name sample-S2-records. We run TextRank with the function top_keywords_sentences with its default settings. We look at keywords and not the representative sentences since an abstract is already a summary of the paper
import json
import codecs
import pandas as pd
import xang_pytextrank as pyt
path=r'D:\sample-S2-records'
a=[]
with codecs.open(path, 'r','utf-8') as f:
for line in f.readlines():
a.append(json.loads(line)['paperAbstract'])
## Remove blank abstracts
a = list(filter(None, a))
t = [pyt.top_keywords_sentences(a[i])[1] for i in range(len(a))]
data=pd.DataFrame({'Abstract':a,'Keywords':t})
data.to_csv('TextRank.csv',index=False)
Complete results are in this folder. This is the result for one abstract:
Abstract
A 26-year-old male suffering from sudden right lower abdominal pain and lumbago was referred to our hospital. Enhanced computed tomography demonstrated bilateral kidneys and spleen infarctions, and a large tumour was found occupying the aortic arch and thoracic descending aorta. We suspected that these infarctions were due to tumour embolization. The aortic arch and thoracic descending aorta were resected with the tumour and then reconstructed using the L-incision technique. A microscopic examination revealed the presence of an intimal sarcoma. The patient was treated with adjuvant chemotherapy and showed a good postoperative course. Neither recurrence nor metastasis has been observed during the 3 years since the operation.
Keywords
tumour embolization, lower abdominal pain, tumour, adjuvant chemotherapy, aorta, arch, aortic arch, course, good postoperative course, l-incision technique, lumbago, bilateral kidneys, descending aorta, large tumour, infarctions, intimal sarcoma
TextRank is able to extract relevant keywords. It can be sped up using multiprocessing.