Webscraping Finviz with Beautiful Soup and Requests
Introduction
Machine learning algorithms are only as good as the data available. Bringing in additional data can give us better insights and improve performance when we have maxed out the performance of the machine learning algorithms. One way to obtain additional data is to scrape websites. Unlike web crawling where search engine bots explore websites and their links, web scraping is specific and seeks to gather large quantities of information from certain websites, for example user comments on special interest forums, product listings, etc.
Check if API available
Before building a scraper, always check if the information can be accessed via APIs. Registration is typically required but using an API would require less effort. Google is your best friend. Certain websites also list out available APIs.
The Requests and Beautiful Soup libraries
To access a website we need to send HTTP requests to servers. The requests library allows us to do exactly that and get the reply from the server in python. The content of the returned request can then be parsed by Beautiful Soup. Usually we are only interested in data contained in certain parts of the website. We will need to identify the section of the html code that contains our data of interest.
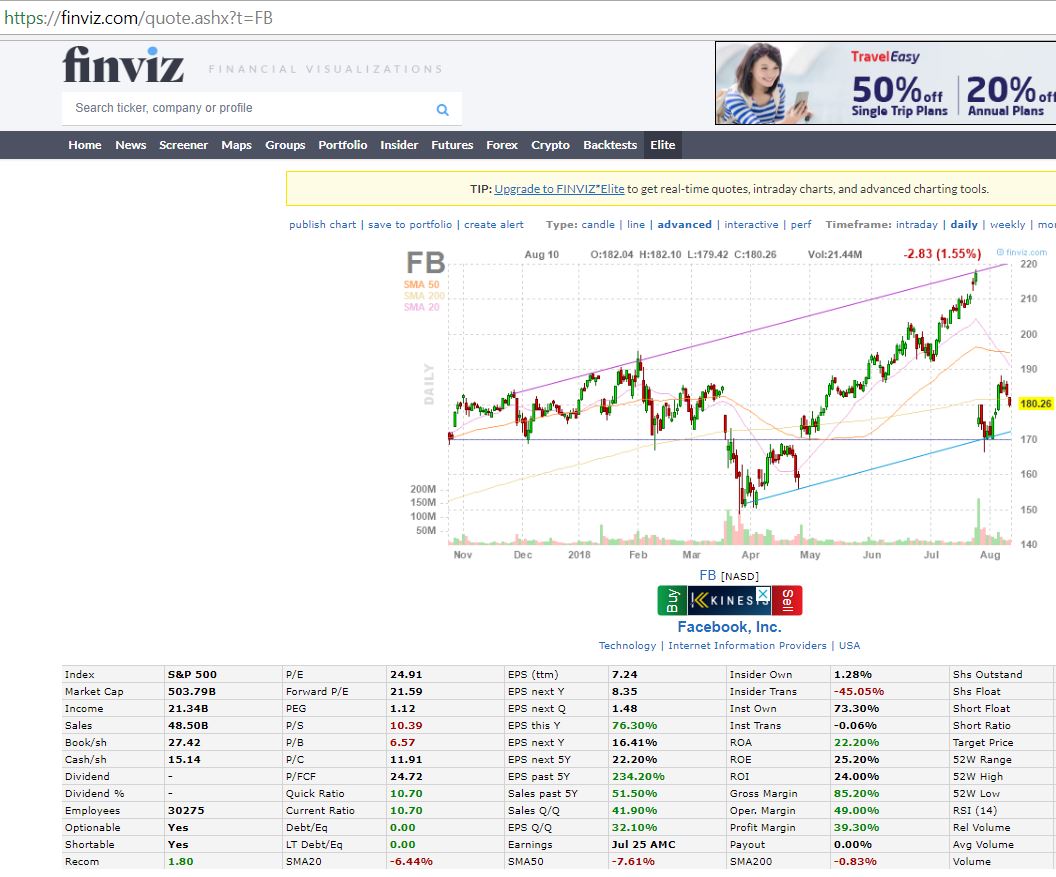
Finviz is a popular US financial visualization website. For each ticker, various substantial technical and fundamental data are displayed. For example, the Facebook ticker has various information available that could be of interest to us in a table. Note that the ticker URL is simply https://finviz.com/quote.ashx?t=FB. By replacing FB with another ticker we can easily write a loop to automate the data retrieval.
import time
import requests
from bs4 import BeautifulSoup
req = requests.get("https://finviz.com/quote.ashx?t=FB")
soup = BeautifulSoup(req.content, 'html.parser')
The code able retrieves the content of the website into soup. We use our web browser to inspect the website to identify the tag, class or id of the table. We can then use the find_all function to isolate the element of interest. In our case one way is to search for all the table tags, select the 9th table and then extract all the rows tagged tr. We can then extract data from all the cells using the td tag.
table = soup.find_all(lambda tag: tag.name=='table')
rows = table[8].findAll(lambda tag: tag.name=='tr')
out=[]
for i in range(len(rows)):
td=rows[i].find_all('td')
out=out+[x.text for x in td]
Handling Errors
Our requests may not all ways get a positive return. The server might have an error, we might request a non existent or retired ticker. In such cases we need to handle the error so that we can continue to scrape the next ticker of interest. There are various HTTP status codes. A simple way is to continue if the error code is not 200 (OK Status).
if req.status_code !=200:
continue
Go slow
Requesting webpages continuously in a loop might cause the server to deny our requests. One workaround is to wait awhile between requests by inserting time.sleep(1) in the request.
Scheduling
If we need to scrape data periodically it is also possible to schedule our scraping script to run at a fixed time via scheduling libraries such as APScheduler
Data Quality
We should also take precautions to check the quality of the scraped data. Certain metrics rely on the stock price to be calculated for example and we should find out which price is being used for the calculation. Metrics could change depending on the time the scarping is done due to changes in the stock price. Other information such as earning’s date can be wrong due to changes.
Finally we get the scrape_finviz function which takes a list of tickers and returns a dataframe with the finviz information.
def scrape_finviz(symbols):
# Get Column Header
req = requests.get("https://finviz.com/quote.ashx?t=FB")
soup = BeautifulSoup(req.content, 'html.parser')
table = soup.find_all(lambda tag: tag.name=='table')
rows = table[8].findAll(lambda tag: tag.name=='tr')
out=[]
for i in range(len(rows)):
td=rows[i].find_all('td')
out=out+[x.text for x in td]
ls=['Ticker']+out[::2]
dict_ls={k:ls[k] for k in range(len(ls))}
df=pd.DataFrame()
p = progressbar.ProgressBar()
p.start()
for j in range(len(symbols)):
p.update(j/len(symbols) * 100)
req = requests.get("https://finviz.com/quote.ashx?t="+symbols[j])
if req.status_code !=200:
continue
soup = BeautifulSoup(req.content, 'html.parser')
table = soup.find_all(lambda tag: tag.name=='table')
rows = table[8].findAll(lambda tag: tag.name=='tr')
out=[]
for i in range(len(rows)):
td=rows[i].find_all('td')
out=out+[x.text for x in td]
out=[symbols[j]]+out[1::2]
out_df=pd.DataFrame(out).transpose()
df=df.append(out_df,ignore_index=True)
p.finish()
df=df.rename(columns=dict_ls)
return(df)